Reverse Integer (Leetcode)
2024-01-15
- Algorithm
- JavaScript
- LeetCode
문제
Given a signed 32-bit integer x, return x with its digits reversed. If reversing x causes the value to go outside the signed 32-bit integer range [-2^31, 2^31 - 1], then return 0.
Assume the environment does not allow you to store 64-bit integers (signed or unsigned).
Example 1:
Input: x = 123
Output: 321
Example 2:
Input: x = -123
Output: -321
Example 3:
Input: x = 120
Output: 21
Constraints:
-2^31 <= x <= 2^31 - 1
접근
스트링화를 하고 split 메서드를 통한 배열화 후, 배열객체를 스택(stack)처럼 생각하고 LIFO 의 특징을 살려서,
하나씩 배열의 앞 쪽에다가 unshift() 를 해준다. 123 -> [3,2,1] 이런식으로 전개가 될 것이다. 그 후 다시 숫자화를 해버리면 된다.
음수 값에 대해서는 배열을 순회하면서 스택에 넣을 때, minus가 존재하는 것에대한 외부 boolean 값을 설정해주고 그에 따라 별도로 Return 해주면 된다.
정답 (맞음)
/**
* @param {number} x
* @return {number}
*/
var reverse = function(x) {
var arr = (x.toString().split(""))
var revArr = [];
var result;
isMinus = false;
for(a of arr){
if(a !== "-") revArr.unshift(a);
else isMinus = true;
}
if(isMinus){
result = -(+(revArr.join('')))
} else result = (+(revArr.join('')))
// result = isMinus ? -(+(revArr.join(''))) : (+(revArr.join('')));
if(Math.abs(result) < -(2**31) || Math.abs(result) > (2**31)-1) return result = 0;
return result
};
문제점
-
부호 처리 : 음수의 경우
- 부호를 처리하는 방식이 비효율적입니다. 배열 전체를 순회하면서 -를 찾는 대신,처음에 x의 부호를 확인하고 처리할 수 있습니다. -
불필요한 형변환: arr를 만들기 위해
x.toString().split("")을 사용하고, 결과를 반환하기 전에+(revArr.join(''))를 사용하는데, 이는불필요한 형변환을 발생시킵니다. -
결과 검증: if 문에서 Math.abs(result)를 사용하는 것은 부적절합니다.
result가 이미 부호가 처리된 상태이므로, Math.abs 없이 result 자체의 범위를 확인해야 합니다. -
변수 선언: isMinus 변수에 var 또는 let 키워드를 사용하지 않았습니다. 이로 인해
전역 변수로 처리될 수 있습니다.
정답 (더 나은 성능)
/**
* @param {number} x
* @return {number}
*/
var reverse = function(x) {
var isMinus = x < 0;
var absX = Math.abs(x);
var revStr = absX.toString().split("").reverse().join("");
var result = parseInt(revStr, 10);
if (isMinus) {
result = -result;
}
if (result < -(2**31) || result > (2**31) - 1) {
return 0;
}
return result;
}
개선된 코드의 설명
-
부호 처리:
isMinus를 사용하여x의 부호를 초기에 확인합니다. -
형변환:
absX.toString().split("").reverse().join("")을 사용하여 숫자를 문자열로 변환하고, 이를 뒤집은 후 다시 정수로 변환합니다. -
결과 검증: 결과의 범위를 직접 확인하여, 32-비트 정수 범위를 벗어나면
0을 반환합니다. -
변수 선언:
isMinus에var를 사용하여 지역 변수로 선언합니다.
이 코드는 주어진 정수를 뒤집고, 결과가 32-비트 정수의 범위 내에 있는지 확인한 후 해당 값을 반환합니다.
궁금했던 점(메서드 차이)
두 메서드 사이의 효율성 차이는 주로 처리 과정과 관련된 연산의 복잡도에 있습니다.
toString().split("").unshift()
-
변환: 숫자를 문자열로 변환합니다 (
toString()). -
분할: 문자열을 문자의 배열로 분할합니다 (
split("")). -
반복 및 삽입: 배열을 반복하면서 각 문자를 새 배열의 시작 부분에 삽입합니다 (
unshift()). 이 과정은 각 반복마다 배열의 모든 요소를 이동시키므로 시간 복잡도가 높습니다.
toString().split("").reverse().join()
-
변환: 숫자를 문자열로 변환합니다 (
toString()). -
분할: 문자열을 문자의 배열로 분할합니다 (
split("")). -
반전: 배열의 요소 순서를 반전합니다 (
reverse()). 이 연산은 배열을 한 번만 순회합니다. -
결합: 반전된 배열의 요소를 문자열로 결합합니다 (
join()).
변경된 메서드 효율성 비교
-
시간 복잡도:
unshift()를 사용하는 방법은 각 문자마다 배열의 나머지 부분을 이동시켜야 하므로 시간 복잡도가 더 높습니다. 반면에reverse()를 사용하는 방법은 전체 배열을 한 번만 순회하므로 효율적입니다. -
간결성과 가독성:
reverse().join()방식은 더 직관적이고 코드가 간결합니다.
결론적으로, reverse().join() 방식은 unshift()를 사용하는 방식에 비해 효율적이며, 코드의 가독성도 더 높습니다.
내 접근법 vs 최적화 접근법 차이
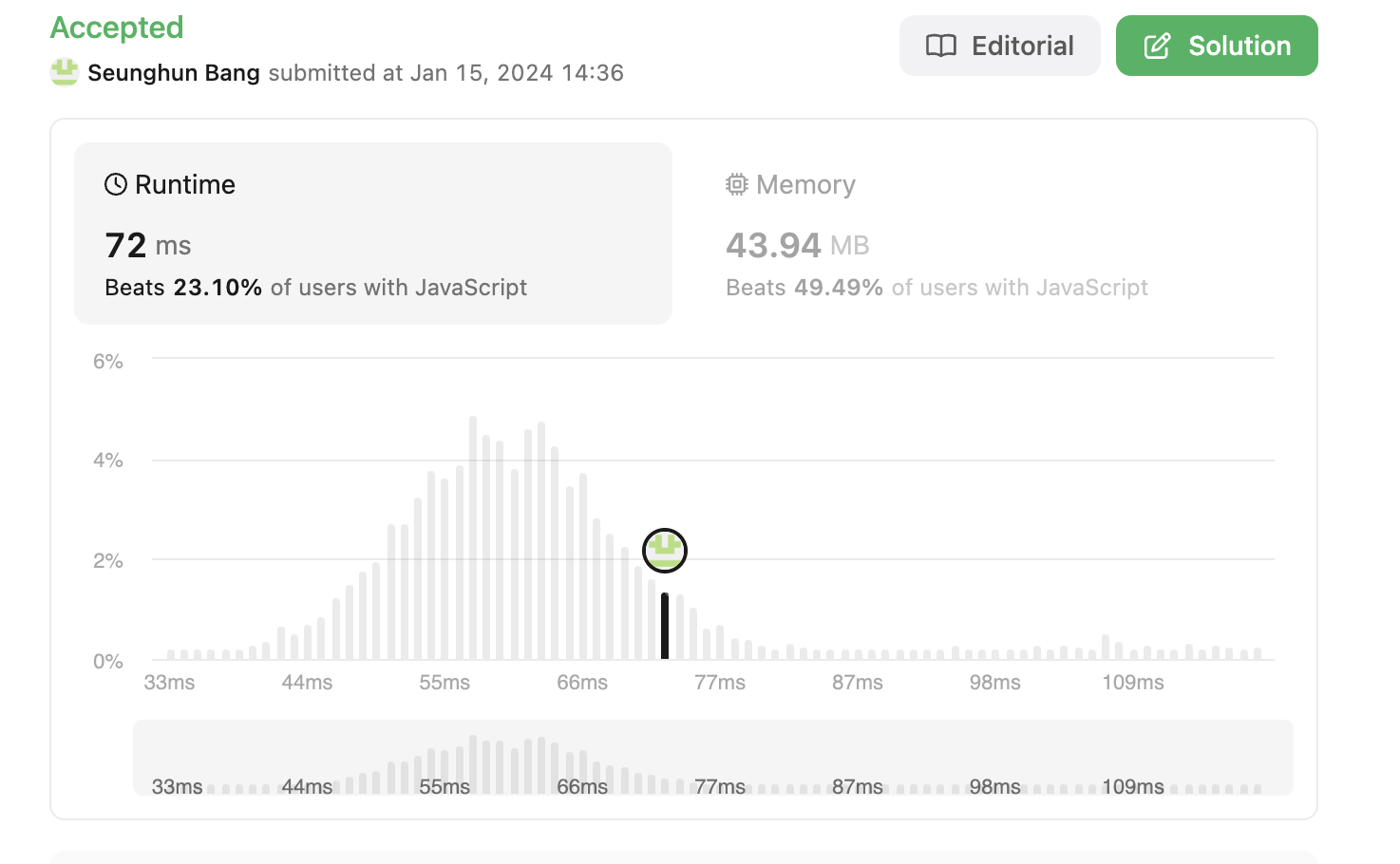
내 접근법
- 반복과 조건 검사: 문자열로 변환한 후, 각 문자를 반복하면서
-부호를 체크하고,unshift메서드를 사용하여 새 배열에 각 문자를 앞쪽으로 추가합니다. - 부호 처리: 음수인 경우를 처리하기 위해 별도의 플래그(
isMinus)를 사용합니다. - 결과 생성: 마지막에 결과를 생성하기 위해
join을 사용하고, 필요한 경우 부호를 바꿉니다.`` - 결과 범위 확인: 결과가 32비트 정수 범위를 벗어나는 경우 0을 반환합니다.
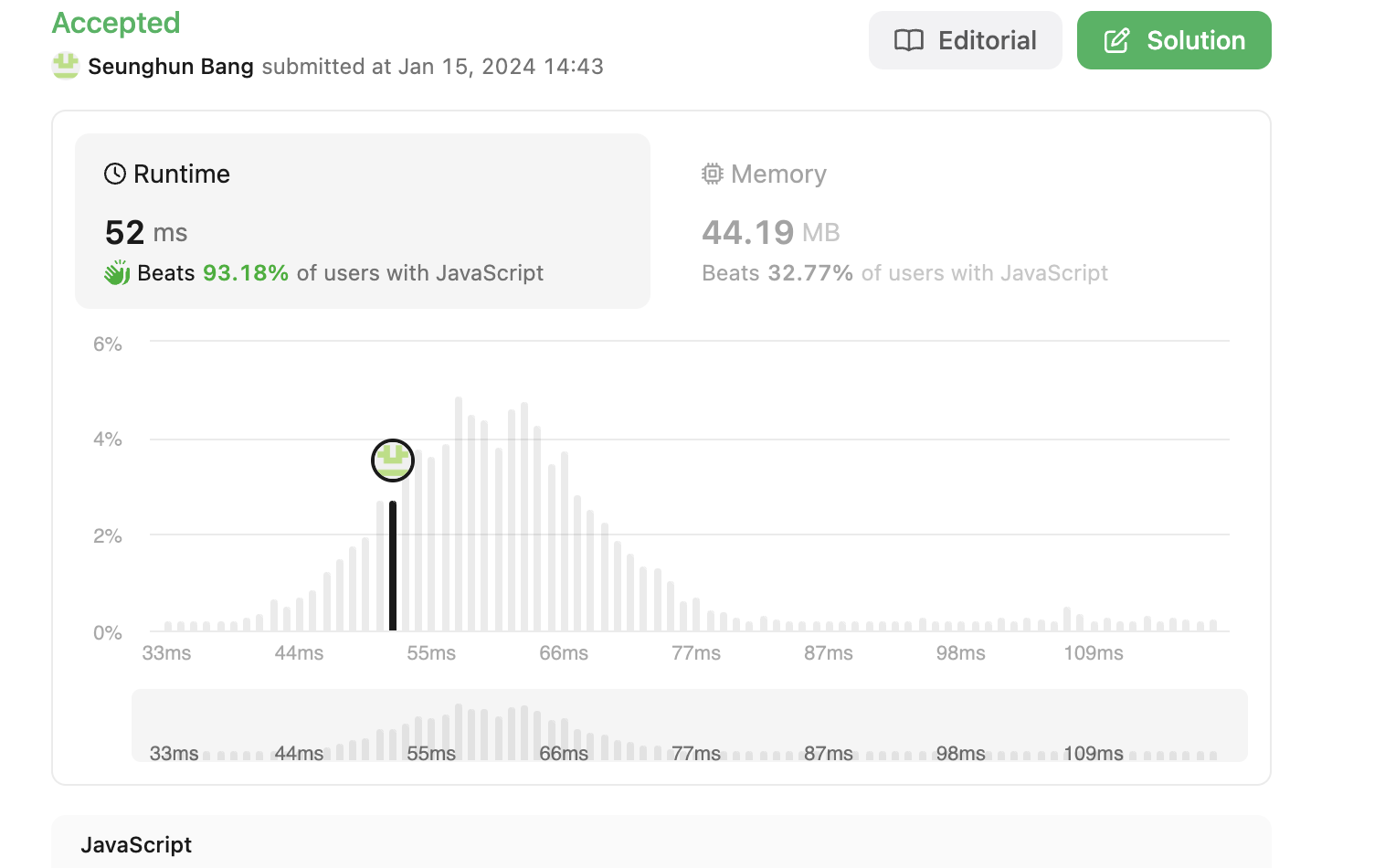
최적화 접근법
- 간결한 반전: 문자열로 변환한 후,
split,reverse,join메서드를 순서대로 체인하여 뒤집은 문자열을 생성합니다. - 효율적인 부호 처리: 음수 여부를 초기에 한 번만 확인하고, 결과에 적용합니다.
- 직접적인 결과 변환:
parseInt를 사용하여 문자열을 정수로 변환합니다. - 결과 범위 확인: 결과가 32비트 정수 범위를 벗어나는 경우
0을 반환합니다.
차이점 요약
- 나의 접근법은 반복문을 사용하여 수동으로 각 문자를 처리하고 부호를 관리하는 반면, 개선된 접근법은 내장 메서드를 활용하여 코드를 간결하고 효율적으로 만듬.
- 개선된 코드는 음수 처리를 더 간단하게 하며,
parseInt를 사용하여 문자열을 정수로 변환하는 과정이 더 직관적. - 두 접근법 모두 32비트 정수 범위를 넘어가는 결과를 처리하는 방식은 동일.
Cypress테스트...
링크드 리스트란(L...